
5 Things Staff MUST Know about Cybersecurity
September 20, 2017In this Issue of the CMG Journal: Using AHP for Performance Audits
October 9, 2017Alibaba Cluster Data Available for Research in Data Center Efficiency
By Zhen Zhang, PhD and Kingsum Chow
Introduction
Several studies have raised the importance of data center efficiency. However, the lack of access to data center performance data has inhibited the progress of improving data center efficiency. To address that problem, Google opened its cluster data to the public in 2011. A great deal of research was generated from that data set. But the research community needs more than just one data set. With that in mind, Alibaba also made its cluster data available.
Alibaba Cluster Data
Alibaba released a resource usage dataset from a production cluster which runs both online services and batch jobs. It contains data over a 24-hour period from 1300 machines.
The data is provided to address the resource inefficiency problem Alibaba faces in a realistic manner, especially for the cluster running user-facing latency critical services. With the help of container technologies, they consolidated these services to increase the resource utilization. But the average resource utilization was still only around 10%. Meanwhile, the big data technology brought along many non latency critical batch jobs. Since 2015, Alibaba has been working on deploying latency insensitive batch jobs along with latency critical online services on the same machines. The successful co-deployment has increased the average resource utilization rate of the cluster from about 10% to more than 40% while meeting the SLO of online services. However, there are many challenges to raise the utilization higher. Hopefully this dataset will facilitate a range of research in cluster management, and especially in the scheduling and co-allocating workloads.
The Alibaba dataset is similar to the cluster data from Google. It includes the following attributes about the cluster:
- Machine spec and workload spec such as CPU, memory and disk space.
- Life cycle Event of workload, such as the adding and removing of a workload instance.
- Actual Resource usage of machines and workload.
- Metrics related to the interference between workload such cycles per instructions and last-level cache misses
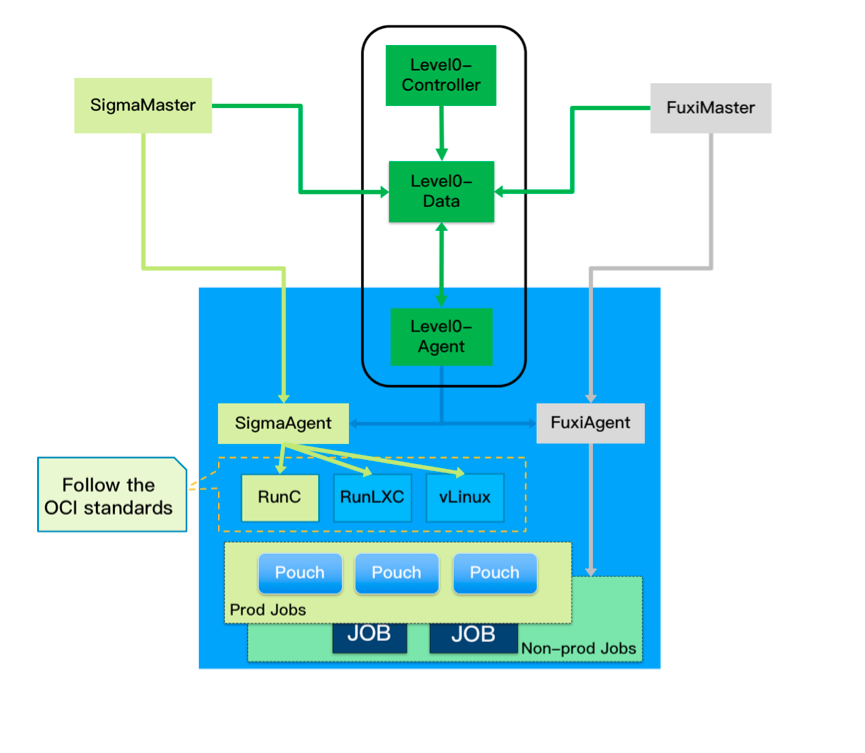
There are some differences in the scheduler architecture and data content between Alibaba and Google. Firstly, workload is managed by two independent schedulers, Sigma and Fuxi, which schedule online services and batch jobs respectively, whereas all workloads were managed by a single monolithic cluster scheduler in Google. Since schedulers for online services and batch jobs differ greatly, the two-scheduler architecture enables both schedulers to evolve independently and rapidly. Secondly, the online services in Alibaba use cpuset cgroup subsystem to isolate CPU resources between online services, and batch jobs use CPU subsystem to limit the CPU usage and to share the CPU usage with online services. Using cpuset, Sigma can have better control of the CPU Hyper-Threading behavior, thus reducing the interference between online services.
This is just the first release of the Alibaba cluster data. More data will be released after evaluating the initial feedback.
We hope the Alibaba cluster data can be useful to the research community in workload characterization and scheduling algorithms.
The location of the Alibaba website is https://github.com/alibaba/clusterdata.
About the Authors
Zhen Zhang, PhD, currently works at Alibaba. He has 11+ years of working experience in IT. He has been working on the cluster management of software applications. He is instrumental in opening Alibaba cluster data to the public. He received a PhD in Computer Science from the Zhejiang University, China. His research interests include capacity planning, resource scheduling and cluster management.
Kingsum Chow is currently the Chief Scientist for Alibaba System Software Hardware Co-Optimization. Since receiving PhD in Computer Science and Engineering from the University of Washington in 1996, he has been working on performance, modeling and analysis of software applications. He has been issued more than 20 patents. He has delivered more than 80 technical presentations. He joined Alibaba in 2016. He can be reached here: https://www.linkedin.com/in/kingsumchow/



{kind=link}
{kind=link}
{kind=link}