
Southwest CMG Virtual Meet-up! (CMG Webinar Series)
May 31, 2017Look inside this Issue of CMG MeasureIT
June 6, 2017For those of us working in the areas of performance management and capacity planning, we frequently use basic statistical procedures to detect patterns, explain current usage, and forecast future capacity requirements. Often we only need basic descriptive statistics in our work, but on occasion may need to take advantage of more complex toolsets such as multivariate linear regression, time series analysis, analytic queuing models, and various kinds of before/after statistical profiling to confirm the effects of software/hardware changes. In addition, we would like to know if there are performance threats affecting operational stability by using monitoring techniques such as multivariate adaptive statistical filtering for outlier detection, threshold monitoring, entropy monitoring, and similar tools.
As the number of systems increase and the amount of system performance data expands, the amount of information explodes into “Big Data” and our efforts must shift away from hands-on deep dive analysis of a few systems toward automated, adaptive, machine-based analysis and monitoring. Most of these techniques are either mathematically sophisticated applications of statistical learning algorithms or the equivalent “engineered solutions” and threshold monitoring. Many of them are new to those of us who are trained in classical statistics and queuing theory.
As Data Science, Data Mining, and other data analytic disciplines have emerged in the application and business areas of IT these new tools are also available for solving problems in machine learning applications in the management of infrastructure performance and capacity. Many of these newer tools are underutilized in the areas of infrastructure operational intelligence. Perhaps it is because we don’t understand them or we think they are not relevant?
In order for the performance analyst to attend to troubled systems that may number in the thousands, it is imperative that we filter out of this vast ocean of time series metrics only those events that are anomalous and/or troubling to operational stability. It is too overwhelming to sit and look at thousands of hourly charts and tables. In addition, there is a need for continuous monitoring capability that detects problems immediately or, better yet, predicts them in the near term. Increasingly, we need self-managing systems that learn and adapt to complex continuous activities and quickly identify the causal reconstruction of threatening conditions as well as recommend solutions (or even automatically deploy remediation events). Out of necessity, this is where we are heading.
The emerging domain of Infrastructure operational intelligence requires that the performance analyst know how to use programming technology to analyze data, mathematics/statistical expertise to explore and understand performance data structures, and an in-depth understanding of infrastructure operational architectures. In summary, they must know more about mathematical statistics than the average infrastructure administrator and more about infrastructure administration that the average mathematician/statistician. Such a person we might call a “Data Scientist” who works in the area of infrastructure service management.
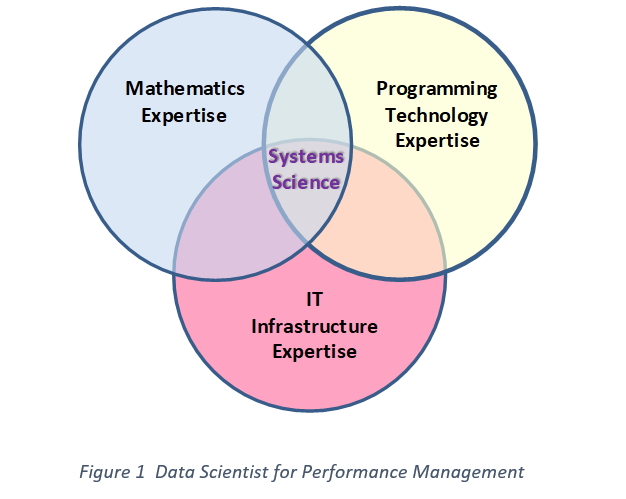
Toolsets to Explore
Experiments require an understanding of proper experimental design. You’ll need to be able to interpret when causal effects are significant, and be able to work with more complicated setups. For example, you want to compare the effects of software changes to a database system. You need a model of how the system behaved before the changes to compare to a model of how it behaved after. You also need statistical techniques to determine if any changes are ‘significant’ or merely chance. Or perhaps you want to speed up a long running process that is I/O bound. So you run “experiments” using synthetic data – random data created with the same statistical properties as ‘real’ data – on buffer size and number of buffers to find an optimal solution that minimizes system time.
Often these are Quasi-experiments or observational studies and more difficult than experiments to analyze. They require a very strong understanding of assumptions and causal models in order to draw convincing conclusions from them. Not everything can be randomized. You might want, for example, to only compare the same days of the week and hours of the day when evaluating CPU demand before and after some change in configuration or function of a specific workload or the entire workload.
Time series are ubiquitous and all infrastructure metrics are based on samples over defined and equal time intervals. With time series analysis you can use past data to forecast the future, or at least estimate it. You may want to use multivariate regression techniques to predict CPU demand based on I/O activity, time of day, day of week (seasonality), CPU demand by various subsystems, etc. combined with a trend model. Perhaps the system state at time t can be used to predict the CPU demand and some later time t+n.
For capacity planning, we use time series analysis to forecast when computing resources will become constrained or depleted based on trend, seasonality and multiple scenarios of business demand for IT services. Ideally, executives have sizing and cost estimates of multiple scenarios that enable various IT projects and may thus choose which projects to fund, shelve, cancel or suspend. It’s important that the proposed configurations not only meet technical requirements but also have an estimated cost.
Time series data can also be used with Logistic Regression to identify “Bad Performance” vs “Acceptable Performance” by comparing training examples. Linear modeling is important and common for regression and classification exercises. It gives you a good framework to combine information from covariates and predict an outcome or class.
Machine learning methods such as clustering, trees, etc. also help with regression, classification, and more complicated modeling questions about infrastructure performance and workload characterization. Perhaps there are extreme statistical events which are detected that are persistent enough to indicate a performance threat or, rather than extreme events, there is a troubling change in the pattern of activity (entropy monitoring). Classification algorithms can help the performance analyst identify ways to characterize workloads based on the performance metrics of the feature space. What features of the performance space best predict high utilization or constraints on limited resources at a later point in time? Can we predict near-future service delivery impact based on current system state? Can we ‘train’ a neural network to keep a watchful eye on how our systems are doing?
In data mining, anomaly detection (also known as outlier detection) is the search for data items in a dataset which do not conform to an expected pattern. Anomalies are also referred to as outliers, change, deviation, surprise, aberrant, peculiarity, intrusion, etc. Most performance problems are anomalies. Probably the most successful techniques (so far) would be Multivariate Adaptive Statistical Filtering (MASF) for detecting statistically extreme conditions and Relative Entropy Monitoring for detecting unusual changes in patterns of activity.
Against the desire for accurate representation one must balance conceptual, mathematical, and computational tractability. We need to understand the mathematical tool and its limitations as well as how to compute the solutions quickly and efficiently. It is of little value to forecast CPU utilization in the next 5 minutes if it takes more than 5 minutes to make the computations.
A detailed exploration of all data science tools is beyond the scope of this paper, but I will highlight some of those most commonly used in data science that should have high utility in performance and capacity management.

Here are some suggestions and recommendations on using the formidable arsenal of data science tools.
When to use Comparative Analysis – You have a huge number of performance metrics to look at such as CPU performance, I/O, memory, Network performance, etc. and you want to know if any of them are ‘unusual’ and ‘stand out’ from the crowd. These metrics are also on vastly different scales of measurements. For each metric take a recent sample and compare that to its history. In the process, rescale all metrics so they can be compared. For example, the current I/O rate, CPU utilization, etc., is compared using:
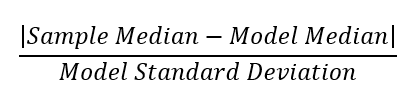
Sort all those calculations from all the metrics high to low. The high ones are the ones of interest. This provides a good proxy for the outliers in the data. This is what ‘stands out’ and is a rough estimate of outliers. These are the ‘hot spots’ needing more analysis.
When to use Multivariate Adaptive Statistical Filtering – You want to determine if the CPU utilization is within the expected range for a certain time-of-day and day-of-week context. You want to confirm that a recent system state has extreme statistical properties, e.g. high CPU or I/O rates, compared to ‘normal operations’. Is the I/O rate ‘too low’ or ‘too high’ compared to its history? What is the normal operating range for this resource on Wednesday between 2:00 PM and 3:00 PM?
As the behavior of systems change over time the statistical filter must be re-computed each time to determine a ‘new’ operational range. This is a classic example of statistical learning.
When to use Entropy Monitoring – You want to know if the pattern of activity (which may include statistical extremes or not) has significantly changed from what is ‘normal’. For example, a system can become saturated on some resource not because of one root cause, but because several workloads are operating in a ‘high normal’ state that, in combination, create too much total activity relative to the capacity. This is also a useful technique to identify system intrusion events (e.g. hackers).
When to use Multivariate Regression (or Logistic Regression) – You want to be able to predict the CPU utilization of a business critical system 5-10 minutes into the future based on its current system state as defined by a few key variables (e.g. CPU, I/O, Memory, etc.). Use multivariate regression techniques to identify the best predictors of emerging statistical extremes or threatening conditions by developing models using lagged values of the performance metrics. Train a logistic model to classify ‘system OK’ and ‘system not OK’ outputs from analysis of input data in which statistical extremes have occurred 5 minutes later.
When to use Time Series Analysis – You have historical data and want to forecast future states of a system resource and discover if there are periodicities in the data such as day of week, time of day, time of month, etc. to adjust your forecast. Perhaps there are surges in demand for computing resources around holidays or other events and you want to be sure you have capacity during those events.
Perhaps you are looking at hourly CPU utilization data over several months and it seems like ‘a cloud of dots’ with no apparent trend or patterns. You might use moving averages to see an underlying trend as well as periodic behaviors. Structure may be hidden by the highly variant hourly metrics but become apparent when averaged over longer intervals.
When to use Neural Nets – Machine learning, computational learning theory, and similar terms are often used to denote the application of generic model-fitting or classification algorithms for predictive monitoring. Unlike traditional statistical data analysis, which is usually concerned with the estimation of population parameters by statistical inference, the emphasis in machine learning is usually on the accuracy of prediction (predicted classification), regardless of whether or not the “models” or techniques that are used to generate the prediction is interpretable or open to simple explanation. Explaining how neural nets work requires in-depth understanding of linear algebra, differential calculus, and gradient descent cost function analysis. Neural network methods usually involve the fitting of very complex “generic” models that are not related to any reasoning or theoretical understanding of underlying causal processes; instead, these techniques can be shown to generate accurate predictions or classification in cross validation samples. In other words, had you trained it on data in the past, it would have made better predictions of computer landscape performance than other statistical methods for prediction.
Neural nets are especially useful when there are many features that need to be mapped to a few response metrics. The use of multivariate linear regression becomes too costly in terms of CPU time when the input features are numerous. In addition, neural nets provide more complex and non-linear solutions when linear classifiers are not adequate.
When to use T-tests and other means testing – Database experts have made changes to a database system to ‘reduce CPU demand’ or ‘speed up I/O waits’. You create comparable samples of the database performance before and after the changes and discover some improvements. Is it statistically significant or could the difference just be due to chance? Is the change the same for low and high activity time periods?
Summary
This is only a brief sketch of the many new analytic tools and new applications of old tools that could benefit performance and capacity management of complex computing landscapes. Academic studies continue to explore these techniques for infrastructure management and operational intelligence but many of us may not be aware of the practical applications of these emerging analytical methods in our work or find it difficult to understand the complex math. The best way to understand it is to work with it and see where it is effective and where it is not.
Author:
Tim Browning,
ITS Consultant – Capacity Planning and Performance Management
Kimberly-Clark Corporation
October, 2015



{kind=link}
{kind=link}
{kind=link}